Last Updated: Tuesday July 20, 2004
Michael Ligh (michael.ligh@mnin.org)
This document is part of the Browser Attacks Anthology
If this was anything frequent or otherwise published I wouldn't be wasting time writing about it here. There was something special about this one - the exploit script was obscured through 3 layers of encoding, while still maintaing the ability to be interpreted by a browser on the fly.
The basic cross-site scripting exploit began by using the WsBASEjpu method, that is explained in great detail on CERT, [1].
As a quick summary: (not to excuse you from reading the whole thing WinkUse an IFRAME element or BASE href to store a target domain or crafted javascript: URL, open a frame in the target domain, and then reference the URL in the same frame (WsBASEjpu, WsFakeSrc).
Using known TARGET values such as _search or _media, an attacker can cause arbitrary HTML (including script) to be evaluated in the Local Machine Zone.
Also, due to the way IE determines the MIME type of a file referenced by a URL, an HTML document may not necessarily have the expected file name extension (.html or .htm).
Here's a piece of the incriminating code, from one of the html files the victim in this case downloaded:
[A HREF=";" TARGET="_search" ID=l2][/A] [script language = JScript.Encode] var xrand='2004071913';
About 784 bytes of jibberish are contained within the <script> tags; obviously encoded in some way shape or form. I found it shockingly impressive that my normal way to decode Jscript.Encode content (see Investigating HTTP based exploits) spits a checksum error and only seems to decode an estimated 1/5 of the content.
The 1/5 that I am able to make out is nothing more than a series of decimal numbers separated by commas. As an example, here is how the script begins after reversing the Jscript.Encode method:
[script language = JScript.Encode>var h=0;var q='';var str=">uetkrv@^@^@hpNqcfKprwv*+=^@^@kh\"*qRgtukuvHqto0qRgtukuvVgzv0xcnwg\"#?\"$vkogtQP$+}^@^@^@^@kh*ykpfqy0pcxkicvqt0crrPcog??$
The main body of code follows and then ends with the string of decimal numbers as such:
119,104,105,108,101,32,40,104,60,115,116,114,46,108,101,110,103, 116,104,41,123,13,10,113,32,43,61,32,83,116,114,105,110,103,46,102, 114,111,109,67,104,97,114,67,111,100,101,40,115,116,114,46,99,104, 97,114,67,111,100,101,65,116,40,104,41,45,50,41,59,13,10,104,43,43, 59,13,10,125,13,10,100,111,99,117,109,101,110,116,46,119,114,105, 116,101,40,113,41,59));[/script]
So now by decoding the first layer of obscurity we are exposed to two additional forms, both different from each other. Getting to the bottom of these seemed a duanting task at first, but they both were conquered with pretty simple solutions.I wrote a small perl script to split each number by the ',' character and use the $letter = chr($x) function to turn the message into plain text. It turned out the long list of numbers was a function itself but the attacker had converted each character from ASCII text to the decimal representation. The decoded function appeared as so:
while (h < str.length){ q +=String.fromCharCode(str.charCodeAt(h)-2); h++; }
Now, for the third set of decoding. I looked up the function str.charCodeAt and it turns out that (str.charCodeAt(h)-2) is an instruction to get the Unicode value of the character at position h-2 of the string (var str). This is all embedded within the fromCharCode method that returns an ASCII character from that Unicode value. The result ends up in a variable named q. So, what is q - that is the question.
I thought about writing some perl to reverse both of these functions and produce something meaninful from the str variable (which contains the large body of unreadable characters). But I almost overlooked the fact that I don't really need to do anything. I can just cut and paste most of the attackers code into my own javascript and make it alert(q) instead.
In case you're wondering, it was easier to alert(q) and take a picture than document.write(q) which messes up because of the CR/LF and other non-html symbols. This is something that confused me from the very beginning - how did these special symbols get there in the first place if the content downloaded by the victim claimed to be of MIME type text/html?
For example, a copy of the encoded script was found in
GET http://216.240.137.41/se/mdg.htm - DIRECT/216.240.137.41 text/html
It was interesting to find that spaces and carriage returns (ENTER) within the script was represented as special characters indicative of binary content (like ^@^?), not text or HTML like normal. Then I stumbled upon the following link that made it all clear. This made sense considering the article above had mentioned incorrect MIME types might be encountered, [2].
A MIME type is ambiguous if it is 'text/plain', 'application/octet-stream', an empty string, or null (that is, the server failed to provide it).
The MIME types 'text/plain' and 'application/octet-stream' are termed ambiguous because they generally do not provide clear indications of which application or CLSID should be associated as the content handlerIf the server-provided MIME type is either known or ambiguous, the buffer is scanned in an attempt to verify or obtain a MIME type from the actual content.
If a positive match is found (one of the hard-coded tests succeeded), this MIME type is immediately returned as the final determination, overriding the server-provided MIME type.
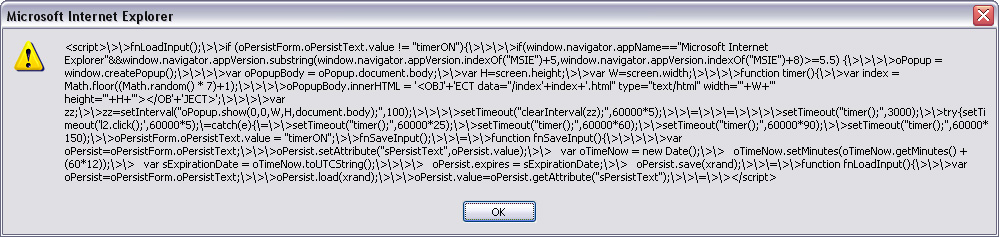
VERY interesting to know. Oh sorry, back to the matter at hand. The image of my javascript alert(q) output:
You might notice the picture shows the variable xrand being passed as a parameter in several function calls. Its not clear exactly what this has to do with the exploit, but the value of xrand is the date it was downloaded (var xrand='2004071913'), The output references oPersistForm and oPersistText several times; this is a form within one of the HTML pages downloaded that submits values to a page named ffeed.php.
This one deserves some credit for being designed in a way that took several independent decoding routines to reveal. It was a good attempt for the attackers to hide their trackers, but not the best.
[1]. US-CERT Advisory Note 771604: IE
does not properly validate source URLs
[2]. Microsoft
MIME Type Detection in IE